Brain Oriented Programming
Video Version:
The 1956 paper The Magical Number Seven, Plus or Minus Two is the most widely cited paper in the 126 year history of the journal Psychological Review. The author George A. Miller is considered one of the founders in the field of cognitive science. His historic claim is that you can only juggle between 5 and 9 things in your brain at any one time.
To my knowledge, despite some controversy over the years, this 7 ± 2 figure has withstood the ongoing reproducibility crisis and it appears to capture a deep truth about how our brains actually function.
Many people are skeptical of the claim because seven sounds like an absurdly small number, surely if you are doing something complex like writing software, or planning a wedding for that matter, you are juggling dozens to hundreds of things? As it turns out you are not. At least not at once.
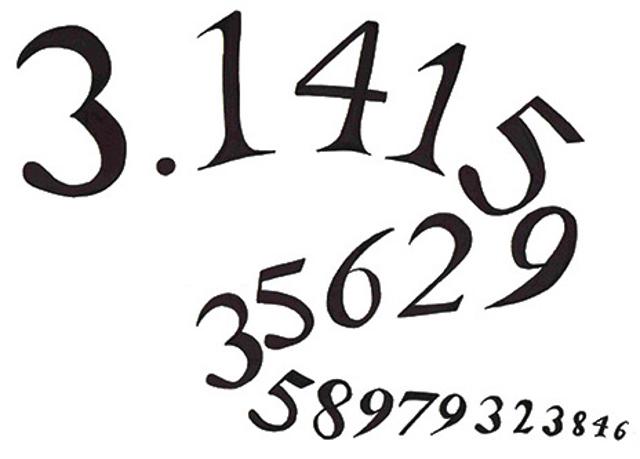
Drawing by Eva Winston, 2020.
In 2005 Lu Chao recited 67,890 digits of Pi, a mind-boggling demonstration of a gifted and well-trained mind. Yet given a series of random single-digit numbers he can on average recall less the than nine of them, to be exact he’s been measured to have a digit span of 8.83 which fits perfectly within Miller’s finding. Amazing!
Chao memorizes Pi the same way story tellers once memorized long tales about Gilgamesh, yet he can only juggle a handful of things at one time. I find this actually to be very comforting, he is not a freak of nature, at least not as freaky as you first thought.
The illusion we can hold many things in mind is almost identical to the illusion that our field of view is high resolution everywhere. It’s incredibly compelling because the instant we wonder what’s over there we do a quick saccade and are immediately rewarded with a high resolution view of exactly what’s over there. We ask the question and we get an instant answer, so it feels like the answer was there the whole time.

This picture exaggerates how big the fovea is, it's actually only about as big as quarter held at arm's length.
Thinking in general works very much like vision. This is not surprising since it’s implemented using the same brain hardware. As we rapidly flit from idea to idea, from concept to concept, we page in the necessary details, but at no time do we have more than about nine individual things in the front of our minds.
How do we navigate a complex world with this seemingly crippling limit on the size of our working memory? Two of the primary tools that we use are chunking and hierarchy.
When we think of a car we naturally divide the car into a handful of high level chunks like the engine, the dashboard, the seats, the wheels. When we mentally zoom into the engine, however, it effortlessly resolves into more parts: the engine block, the pistons, the spark plugs. And we can keep zooming in, although how far we can zoom in highly depends on how much we know about cars and the world in general.
In Object Oriented Programming one of the simplest ways to tame complexity is to limit your objects to around seven attributes. In some languages attributes are called member variables or fields. Many programmers immediately balk at this suggestion. Sure, that works for toy examples, but I’m writing serious software and my objects sometimes need 10, 20 or 50 attributes. You must be working on easy stuff, they will say. My problems are special, so my code has to be different.
The biggest trap of software development is that it’s easy, trivial in fact, to write software that you yourself cannot understand, and in turn no one else can understand. Even a novice, especially a novice, can in a few weeks write software that literally no one on the planet can easily think or reason about. That’s depressing, but also kind of impressive in a way. With great power comes great responsibility.
Objects which have too many attributes are a major cause of software that’s too complicated to understand. Some people conclude the problem is Object Oriented Programming itself. This is not a crazy idea, there are other ways to program, and they do have advantages, but in my experience most of the flaws attributed to Object Oriented Programming stem from having done it poorly, and boy is it easy to do poorly.
Complexity grows without bound.
The key thing to realize is a single object with a lot of attributes is itself not Object Oriented. Instead, it’s a 1970s style Structured Program in disguise. The attributes of the object are the global variables of the program, and the object’s methods are the program’s functions. Every function can freely access every global variable which is what causes many of the problems.
A structured program with more than seven global variables is trouble, and if many objects in your program are effectively messy structured programs themselves, you are in serious trouble indeed. At a high level you are doing Object Oriented Programming, but at a low level you are right back in the 1970s struggling to deal with one confusing program after the next.
How do we save this sinking ship? We save it by actively and aggressively keeping the number of attributes per object at or below seven. If you fail to do this you are punting the problem to your future self, a problem that by definition your future self is going to have a hard time solving.
Just today I had a Python class called
PerfEvent with these attributes:
self.name = name
self.start_ns = start_ns
self.end_ns = end_ns
self.category = category
self.process_id = process_id
self.thread_id = thread_id
self.args = kwargs
self.phase = phaseThat’s eight attributes, since eight is only one over the limit, should we
wait until the object grows bigger? No, let’s deal with it now. To reduce
the number of attributes we introduce two new classes or structs: Span
and Origin. Each only has two attributes, but now the original object has
been slimmed down to six attributes, all is well again:
self.name = name
self.span = Span(start_ns, end_ns)
self.category = category
self.origin = Origin(process_id, thread_id)
self.args = kwargs
self.phase = phaseAlthough it’s a minor change, compare the two versions, the improved one simply looks better, even if you stand far back and squint.
It seems minor, but if you don’t make these types of changes as you go it will eventually lead to intractable complexity, the type of complexity that causes projects and companies to fail, the type of complexity that seduces humans into wasting billions of dollars every year writing software that does not work.
The benefits of introducing sub-objects goes far beyond just reducing the
number of attributes. While accessing the attributes is slightly more
verbose, I like the sound of self.span.start_ns compared to just
self.start_ns, but more importantly we can now pass Span’s and
Owner’s to functions, slimming down and chunking their argument lists.
We’ve introduced two natural and useful concepts that will pay ongoing dividends, but even better don’t just think of how your code is today, think about how it’s going to grow over time. Your single monolithic object has sprouted two buds. You can now push functionality down into these buds, and they can grow into branches, which later can sprout buds of their own.
For example we can now give Span a get_duration_ns() method. Again it seems
minor, but writing span.get_duration_ns() is better than writing
span.end_ns - span.start_ns especially if you are going to do that in
many different places.
The real magic though is that the benefits of being disciplined will accrue like compound interest as you convert your monolithic object into an intricately structured tree which buds and sprouts and branches organically. You will benefit from this better design every minute you are working on the software, and the software will benefit greatly from your improved mood and ability to sustain focus.

A carefully tended Bonsai tree.
Code, like most human created artifacts, can be beautiful, so there is an aesthetic pay off here, but the real jackpot is that if you assiduously tend and groom this tree you will create a software design that slides into your head with minimal fuss and friction, and slides similarly into the heads of other people.
It’s no accident that we find natural environments to be more soothing than the made world, than the concrete jungle. The design of the natural world tends to be more in harmony with how our brains think about that world. Game recognizes game.
Over time, you will grow a system that you and others can understand, maintain, debug and extend. When people look at your code years from now, maybe even in the far future, they will benefit from your diligence and hard work. And the punchline is doing all this is not hard. In fact, it’s much easier to do this work than not to not do it.
It’s easier and more pleasant to work with something that’s well crafted and simpatico with your thinking. It’s hard and unpleasant to constantly wrestle with something you don’t understand. Trim, prune and shape your objects early and often. Your brain will thank you.
See Also:
- Hacker News comments on this article.
- Find your own digit span with this Digit Span Memory Test.
- Some Chimpanzees have better working memory than humans!
Postscript on APIs:
The article discusses objects and attributes, not methods and APIs. NumPy’s ndarray has 15 attributes but 50 methods. That’s totally fine, but imagine the opposite, if it had 50 attributes? That would be a mess.
Attributes are global variables in the structured program that is the object, so each additional attribute potentially complicates the implementation of every other method in the object, present and future.
In contrast, adding a new method is just adding a new useful thing you can do with that object, it doesn’t hurt the existing methods at all. This is part of the reason Functional Programming encourages functions. The only real cost of huge flat APIs is documentation and discovery, the programmer needs to be able to find what they need.
Creating a nicely balanced tree of objects as the implementation and then adding a flat API layer on top is sometimes the best of both worlds. Microservices lean towards this approach, they tend to have flat REST APIs, but inside they are free to use whatever implementation architecture makes sense.
Postscript on Mutable State:
An object with four boolean variables can be in one of 16 possible states. In theory every method of that object needs to work correctly in all 16 of those states. An object with 10 boolean variables has 1024 possible states. Every boolean attribute you add to an object doubles the number of possible states the object can be in. This is a big reason why limiting the number of attributes per object is a good idea.
Functional Programming usually advocates “no mutable state”. Applying this to OOP your object’s state should not change over its lifetime. An object with 1024 posible states is insane enough, but if that object hops around willy nilly in that state space over time, that’s the stuff of nightmares, and that’s daily life in many large OOP codebases.
Postscript on real-world OOP:
Large messy OOP codebases are maintained and extended only if they’ve become become economically valuable. If your product is making more and more money, you can afford to hire more and more smart programmers to keep the party going. This leads to a survivorship bias where large actively maintained OOP codebases tend to be counter-examples towards how to do OOP well, serving as a bad example on the impressionable minds working on the code. Those who realize this might be tempted to start fresh on a new codebase, possibly at a new company.